.net 信息采集ajax数据
关于.net信息采集的资料很多,但是如果采集的网站是ajax异步加载数据的模式,又如何采集呢?今天就把自己做信息采集时,所遇到的一些问题和心得跟大家分享一下。
采集网站的几种方式与利弊:
- HttpWebRequest
利用系统自带HttpWebRequest对象,采集网站内容,优点是采集效率快,但是如果网站是ajax异步加载数据的方式,是采集不到网页内容的,并且网站没有采用ajax的方式,在网页中用到了javascript,比如说:网页内容用document.write的方式输出到网页中的,这种情况也是获取不到内容的。其次还需要知道对方网站的编码格式(就是网页头部中<meta charset="utf-8"/>),如果采集时网站编码格式错误的话,会导致采集的内容是乱码。但这个是小问题,我自己当时查阅资料时找到了别人封装好的方法,但是很惭愧因为不知道作者是谁了,我会把相应的代码下载链接提供给大家。以上的问题是因为js和ajax是需要浏览器去解析的,所以导致了获取不到网页内容。
Help.HttpHelp.HttpRequest("采集的网址"); 2.浏览器控件
因为当时我开发的时候,用的是cs模式,相信大家同样也会用cs的模式去开发这个功能。既然是cs模式(不考虑美观)的情况下肯定是WinForm,WinForm中有自带的浏览器控件,这个是不好用的,我当时用的是Geckofx,基于火狐内核的一款浏览器控件,但是这方面的资料很少,当时遇到了一些问题都找不到解决方法,但后来还是都解决了。用了该控件就可以获取到ajax异步加载的数据,在网页加载完成之后,延迟几秒钟获取网页内容,就可以很方便的获取到网页内容,缺点是相对第一种方案来说的话会慢一些,因为它是一个浏览器控件,需要渲染html和解析js等操作。
GeckoWebBrowser webBrowser = null; private void Form1_Load(object sender, EventArgs e) { string xulrunnerPath = AppDomain.CurrentDomain.BaseDirectory + "\\bin"; Xpcom.Initialize(xulrunnerPath); //设置为3阻止所有的弹出窗口, GeckoPreferences.User["privacy.popups.disable_from_plugins"] = 3; //禁止加载图片 GeckoPreferences.User["permissions.default.image"] = 2; webBrowser = new GeckoWebBrowser(); webBrowser.Navigate("http://www.baidu.com"); webBrowser.DocumentCompleted += DocumentCompleted; } private void DocumentCompleted(object sender, Gecko.Events.GeckoDocumentCompletedEventArgs e) { var time = new System.Windows.Forms.Timer(); time.Interval = 2000; time.Tick += (a, b) => { time.Stop(); string html = ""; //页加载完成 GeckoHtmlElement element = null; var geckoDomElement = webBrowser.Document.DocumentElement; if (geckoDomElement != null && geckoDomElement is GeckoHtmlElement) { element = (GeckoHtmlElement)geckoDomElement; //网页内容 html = element.InnerHtml; txtHtml.Text = html; /* //通过xpath 查找class为btnLogin的元素 GeckoNode btnLogin = webBrowser.Document.SelectFirst(".//*[@class='btnLogin']"); if (btnLogin != null) { GeckoHtmlElement ie = btnLogin as GeckoHtmlElement; //手动触发点击事件 ie.Click(); }*/ } }; time.Start(); }
3.phantomjs
phantomjs可以把它理解为也是一个浏览器控件,只不过它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码。利用该组件就可以很方便的获取到网页内容,同时也包括了ajax加载的数据,如果是分页的情况下,首次加载不需要延迟,如果获取第2页及以上内容的话同样也需要延迟才能获取到,并且它可以很方便的完成网页快照(就是网页截屏),至于其他的功能大家可以自己查阅一下资料。
IWebDriver driver = null; private void btnGo_Click(object sender, EventArgs e) { string phantomjsDire = AppDomain.CurrentDomain.BaseDirectory; PhantomJSDriverService service = PhantomJSDriverService.CreateDefaultService(phantomjsDire); service.IgnoreSslErrors = true; service.LoadImages = false; service.ProxyType = "none"; driver = new PhantomJSDriver(phantomjsDire); /*IWindow iWindow = driver.Manage().Window; iWindow.Size = new Size(10,10); iWindow.Position = new Point(0, 600);*/ driver.Navigate().GoToUrl(textBox1.Text); string html = driver.PageSource; txtHtml.Text = html; //driver.Close(); //driver.Quit(); } private void btnPage_Click(object sender, EventArgs e) { // .//*[@class='next'][text()='下一页'] // .//*[@class='text'] // .//*[@class='button'] //IWebElement element = driver.FindElement(By.XPath(".//*[@class='text']")); //给网页中文本框赋值 //element.SendKeys("4"); IWebElement btnElement = driver.FindElement(By.XPath(".//*[@class='next'][text()='下一页']")); btnElement.Click(); var time = new System.Windows.Forms.Timer(); time.Interval = 2 * 1000; time.Tick += (a, b) => { time.Stop(); string html = driver.PageSource; txtHtml.Text = html; }; time.Start(); } 网站内容中url地址如果是相对地址的话,就是../../a.html,这种情况要想获取绝对地址的话,可以用以下方法:
////// 获取绝对url地址 /// /// 当前页地址 /// 相对路径地址 ///public static string GetRealUrl(string baseUri, string relativeUri) { try { baseUri = System.Web.HttpUtility.UrlDecode(baseUri); relativeUri = System.Web.HttpUtility.UrlDecode(relativeUri); Uri baseUriModel = new Uri(baseUri); Uri uri = new Uri(baseUriModel, relativeUri); string result = uri.ToString(); baseUriModel = null; uri = null; return result; } catch (Exception ex) { } return relativeUri; }
总结:
以上说的第2、3种方式都可以获取到ajax异步加载的内容,同时还能通过xpath模式查找网页中的元素,例如分页标签和按钮,找到元素之后可以调用click点击事件,就能轻松的解决分页问题。好多网站分页分到最后一页的时候,处理的情况都不一样,需要自己去处理,例如有的隐藏下一页按钮、有的是禁用等等。
获取到网页内容之后,要想获取自己需要的内容,可以通过HtmlAgilityPack插件,它是通过xpath的模式查找内容。
以下我会将自己开发的信息采集系统截图发出来。
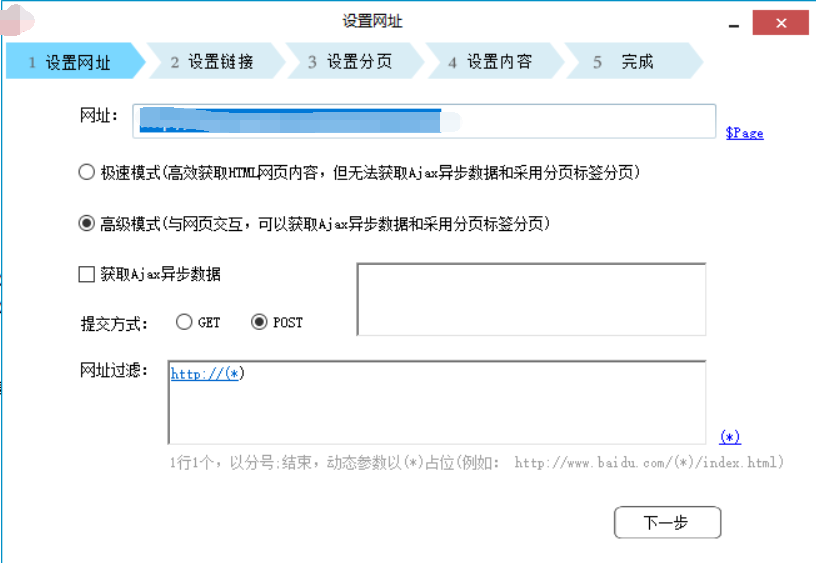
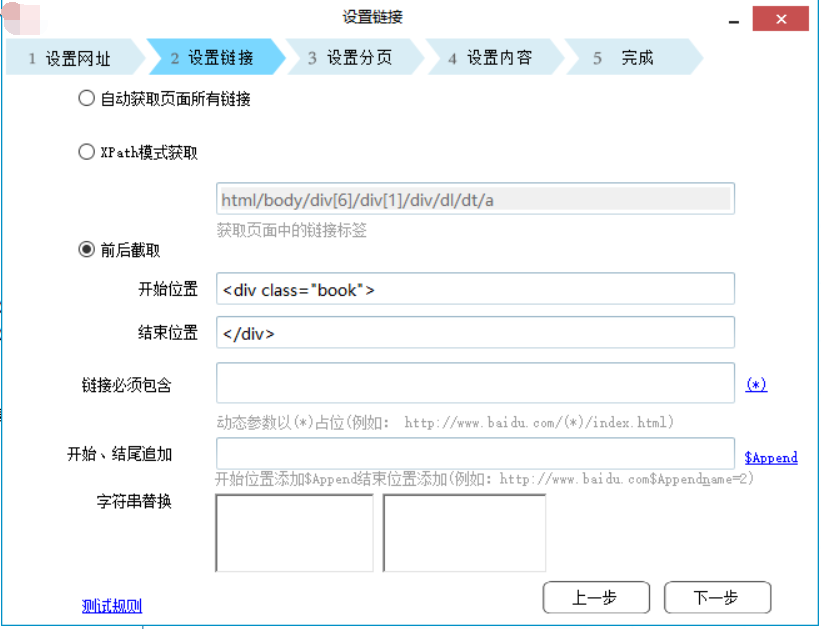
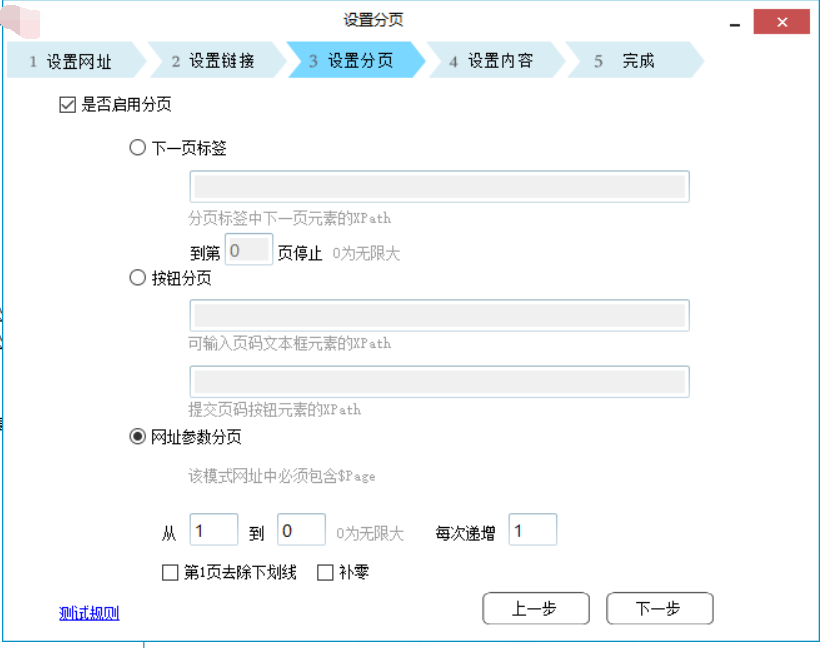
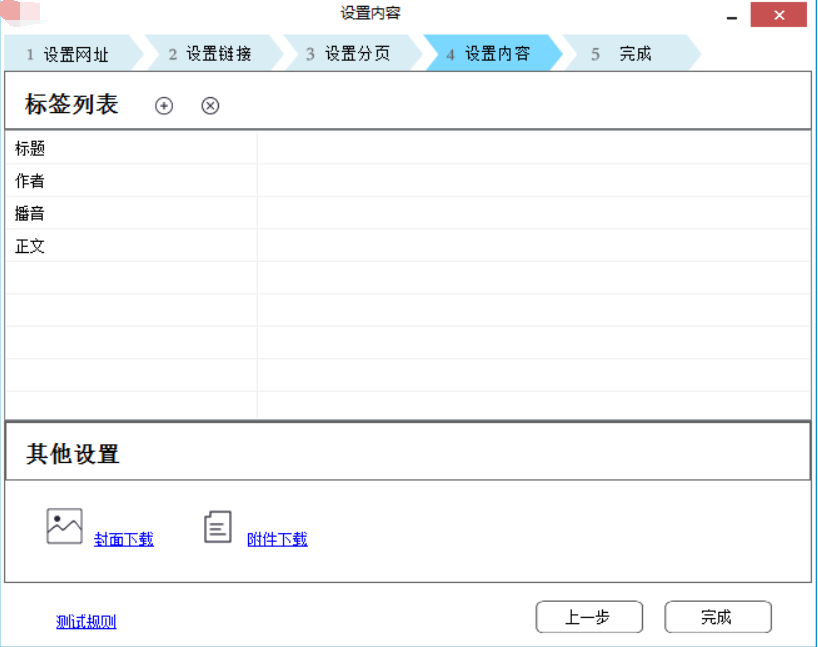
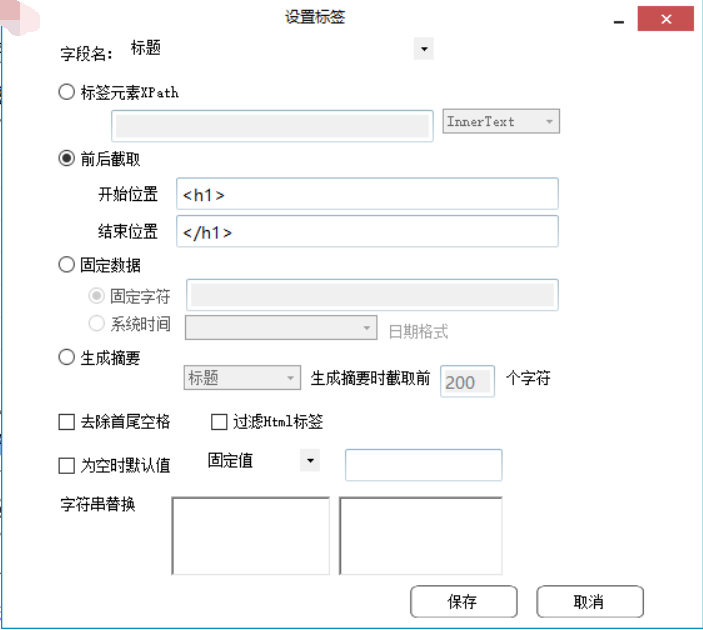
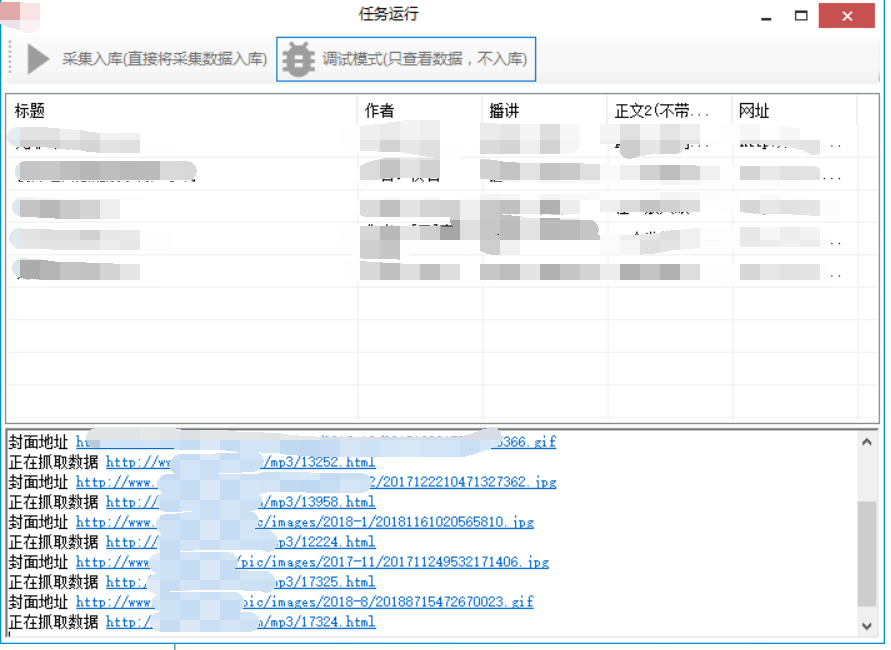
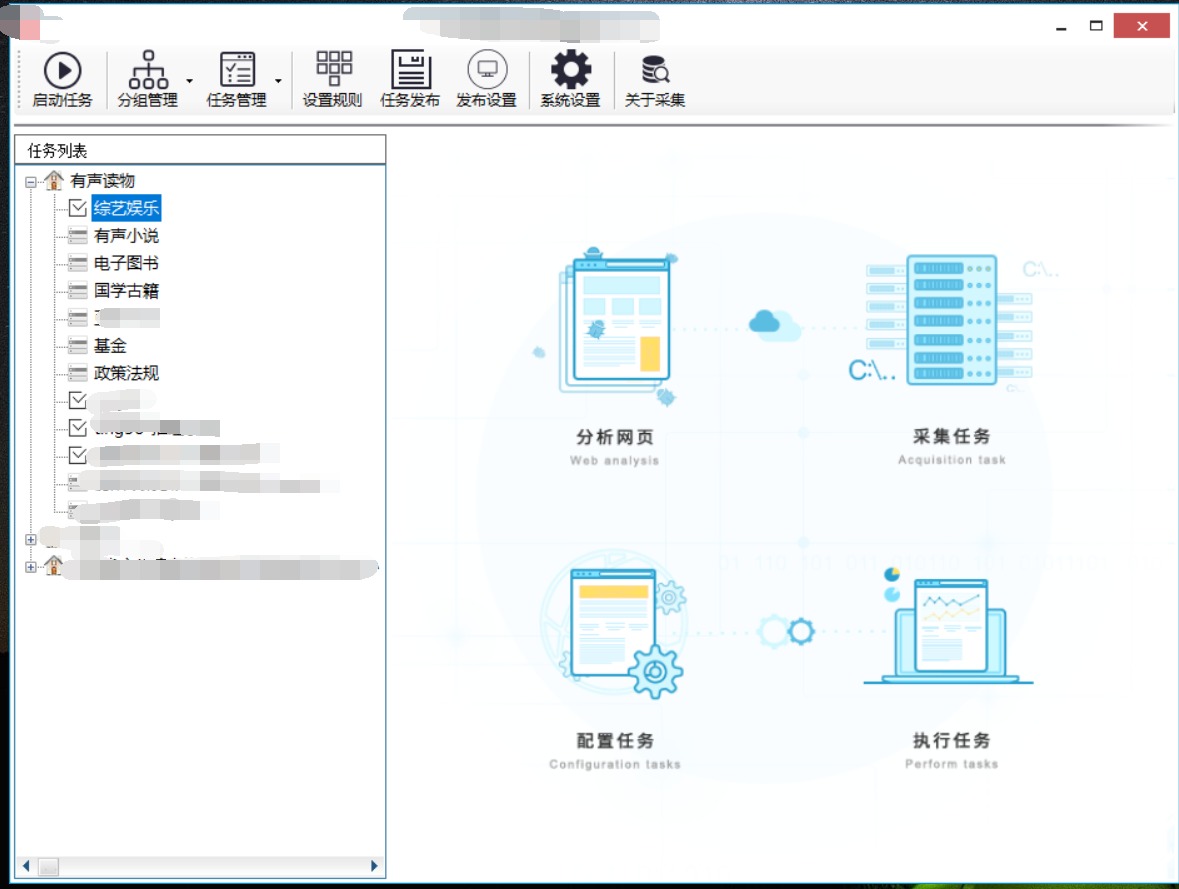
欢迎任何形式的转载,但请务必注明出处。
文案功底有限,码字不易,不喜勿喷,如果文章和代码有表述不当之处,还请不吝赐教。